

في عالم يشهد تطورًا تقنيًا متسارعًا، أصبحت خوارزميات الذكاء الاصطناعي هي المحرك الأساسي للعديد من التطبيقات والخدمات الذكية التي نستخدمها يوميًا، من التوصيات على منصات البث، إلى أنظمة القيادة الذاتية، وحتى المساعدات الرقمية. هذه الخوارزميات ليست مجرد تعليمات برمجية، بل تمثل نماذج رياضية معقدة تحاكي طريقة تفكير الإنسان واتخاذه للقرارات. يزخر مجال الذكاء الاصطناعي بالعديد من الخوارزميات، إلا أن بعضًا منها اكتسب شهرة وانتشارًا واسعًا بفضل كفاءته العالية وتعدد استخداماته. في هذا المقال، نستعرض أكثر 13 خوارزمية شهرة في مجال الذكاء الاصطناعي، موضحين كيف تعمل، ولماذا تُستخدم، وما يميز كل واحدة منها عن الأخرى .
ما هي خوارزميات الذكاء الاصطناعي؟
خوارزميات الذكاء الاصطناعي هي مجموعة من التعليمات والخطوات الرياضية والمنطقية التي تمكّن الأنظمة الحاسوبية من محاكاة السلوك البشري الذكي، مثل التعلم، والتحليل، واتخاذ القرارات، وحل المشكلات. تستخدم هذه الخوارزميات البيانات بشكل مكثف، حيث يتم تدريب النماذج الحاسوبية على كميات ضخمة من المعلومات لاكتشاف الأنماط والتنبؤ بالنتائج المستقبلية. تختلف خوارزميات الذكاء الاصطناعي في طبيعتها ووظيفتها، فمنها ما يُستخدم في تعلم الآلة (Machine Learning) مثل خوارزمية الانحدار الخطي، وخوارزميات الأشجار، والشبكات العصبية الاصطناعية، ومنها ما يُستخدم في الذكاء الاصطناعي الرمزي القائم على القواعد (Rule-Based Systems). وتُعتبر الشبكات العصبية العميقة (Deep Neural Networks) من أبرز التطورات الحديثة التي أحرزت تقدمًا كبيرًا في مجالات مثل معالجة اللغة الطبيعية، والتعرف على الصور، والتنبؤ السلوكي. تعمل هذه الخوارزميات من خلال خطوات تشمل إدخال البيانات، ومعالجتها، واستخراج العلاقات ذات الصلة، ثم التوصل إلى استنتاجات أو قرارات تعتمد على ما تم تعلمه سابقًا. ويزداد دور خوارزميات الذكاء الاصطناعي أهمية في العصر الرقمي، إذ تُستخدم في تطبيقات متعددة تشمل الرعاية الصحية، والخدمات المالية، والمساعدات الرقمية، وتحسين سلاسل التوريد، والتعليم الذكي، وغيرها. كما أن فعالية هذه الخوارزميات تعتمد على جودة البيانات، وطريقة تصميم النموذج، ومدى تطور البنية التحتية التقنية المستخدمة. وبالتالي، فإن خوارزميات الذكاء الاصطناعي تُعد العمود الفقري لأي نظام ذكي يسعى لمحاكاة العقل البشري وتعزيز كفاءة العمل والإنتاج في مختلف المجالات .

أهمية الخوارزميات في تطوير تطبيقات الذكاء الاصطناعي
تلعب الخوارزميات دورًا جوهريًا في تطوير تطبيقات الذكاء الاصطناعي، إذ تُعد الأساس الرياضي والمنطقي الذي تعتمد عليه هذه التطبيقات في معالجة البيانات واتخاذ القرارات. تقوم الخوارزميات بتحديد كيفية تحليل المدخلات، وكيفية التعلم منها، ومن ثم توليد المخرجات المناسبة بناءً على ذلك. وتتمثل أهمية الخوارزميات في عدة جوانب رئيسية :
- تمكين التعلم الآلي : تعتمد تقنيات التعلم الآلي (Machine Learning) والتعلم العميق (Deep Learning) بشكل أساسي على خوارزميات معقدة تقوم بتدريب النماذج على كميات ضخمة من البيانات، مما يمكن الأنظمة من التعلم الذاتي وتحسين أدائها بمرور الوقت دون تدخل بشري مباشر .
- تحليل البيانات واستخلاص الأنماط : تتيح الخوارزميات تحليل البيانات الضخمة والكشف عن أنماط وعلاقات غير مرئية، مما يساعد في اتخاذ قرارات دقيقة في مجالات مثل الرعاية الصحية، والتجارة الإلكترونية، والتمويل .
- تحسين الكفاءة والدقة : بفضل الخوارزميات، يمكن لتطبيقات الذكاء الاصطناعي العمل بكفاءة عالية وتقديم نتائج دقيقة وسريعة، وهو ما يساهم في خفض التكاليف وتحسين الإنتاجية .
- دعم التنبؤ واتخاذ القرار : تستخدم الخوارزميات التنبؤية في تحليل الاتجاهات المستقبلية، مثل توقع سلوك العملاء أو تحركات السوق، مما يعزز قدرة المؤسسات على اتخاذ قرارات استراتيجية مدروسة .
- توسيع نطاق الاستخدامات : الخوارزميات هي المحرك الأساسي لتطوير حلول ذكاء اصطناعي قابلة للتطبيق في مجموعة واسعة من المجالات، مثل السيارات ذاتية القيادة، والمساعدات الافتراضية، وأنظمة التوصية .
بالتالي، فإن الخوارزميات تمثل العمود الفقري لتطبيقات الذكاء الاصطناعي، ومن دونها لا يمكن تحقيق الفاعلية أو المرونة أو القدرة التنبؤية التي تميز هذه التقنيات .
أهم خوارزميات الذكاء الاصطناعي
.1 خوارزمية الانحدار الخطي (Linear Regression)
تُستخدم لتوقع القيم العددية بناءً على علاقة خطية بين متغيرين أو أكثر .
تعتمد على رسم خط أفضل ملاءمة يمثل العلاقة بين المدخلات والمخرجات .
مناسبة لحالات مثل توقع أسعار المنازل، أو المبيعات حسب الوقت .
تعطي نتائج سهلة التفسير ويمكن تمثيلها بصريًا بسهولة .
تعاني من ضعف الأداء في حال كانت العلاقات غير خطية .
تُستخدم كخوارزمية أساسية في النماذج التنبؤية البسيطة .
سريعة التنفيذ وتتطلب موارد حسابية قليلة مقارنة بالخوارزميات المعقدة .
.2 خوارزمية الانحدار اللوجستي (Logistic Regression)
رغم اسمها، فهي تُستخدم في التصنيف وليس التنبؤ العددي .
تُستخدم لتصنيف البيانات إلى فئتين مثل: نعم/لا أو ناجح/فاشل .
تعمل عبر حساب احتمال انتماء العينة إلى فئة معينة .
تُستخدم على نطاق واسع في تصنيف البريد المزعج، وتشخيص الأمراض .
مناسبة عندما تكون العلاقة بين المتغيرات غير خطية .
قابلة للتفسير وتوفر احتمالات بدلاً من مجرد تصنيفات .
تعتمد على دالة لوجستية (Sigmoid) لضغط القيم في نطاق 0 إلى 1 .
.3 خوارزمية شجرة القرار (Decision Tree)
تعمل عبر تقسيم البيانات إلى فروع وفقًا للميزات الأكثر تأثيرًا .
كل عقدة في الشجرة تمثل اختبارًا، وكل فرع يمثل نتيجة .
سهلة التفسير والتمثيل، وتعمل جيدًا مع البيانات غير الخطية .
تُستخدم في تصنيف البيانات واتخاذ القرارات التنبؤية .
مناسبة في التعليم الآلي، والتسويق، وتحليل المخاطر .
تعاني من الإفراط في التخصيص (Overfitting) ما لم تُضبط بشكل جيد .
يمكن استخدامها كنواة لخوارزميات أكثر تعقيدًا مثل الغابات العشوائية
.4 خوارزمية الغابات العشوائية (Random Forest)
تجمع عدة أشجار قرار لتقليل احتمالات الخطأ والتخصيص المفرط .
تعتمد على مبدأ "تصويت الأغلبية" للحصول على التنبؤ النهائي .
توفر دقة أعلى من شجرة القرار الواحدة .
تُستخدم في التصنيف، التنبؤ، وتحليل البيانات الطبية .
مقاومة للضجيج وتعمل جيدًا مع مجموعات بيانات كبيرة .
تقلل من التحيز وتحسن أداء النماذج التنبؤية .
تُعد خيارًا مثاليًا للأنظمة الذكية المعقدة .
.5 خوارزمية الجار الأقرب (K-Nearest Neighbors - KNN)
تصنّف البيانات اعتمادًا على التشابه مع أقرب "K" نقاط في التدريب .
كل نقطة تُصنَّف حسب تصويت أغلبية جيرانها الأقرب .
تُستخدم في التعرف على الصور، ونُظم التوصية، وتشخيص الأمراض .
بسيطة لكنها بطيئة في التنفيذ على البيانات الضخمة .
تعتمد كفاءتها على اختيار قيمة "K" المناسبة .
لا تحتاج إلى تدريب مسبق (Non-parametric) لكنها ثقيلة حسابيًا .
تُظهر أداء جيدًا في حالات تكون فيها البيانات موزعة بوضوح
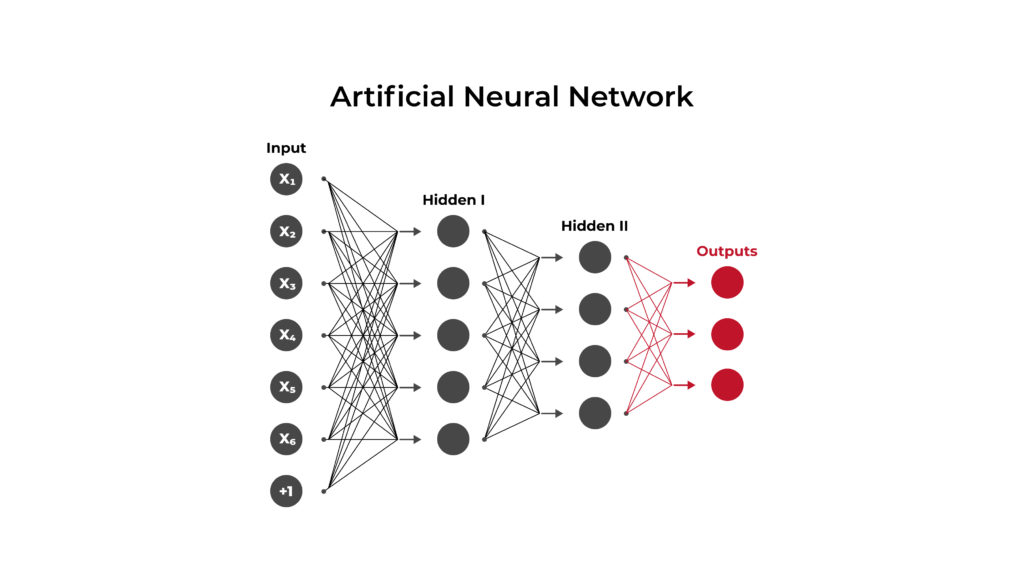
.6 خوارزمية الدعم الناقل (Support Vector Machine - SVM)
تُستخدم للفصل بين الفئات من خلال إيجاد "الحد الفاصل الأمثل ".
تعمل على تعظيم المسافة بين الفئات المختلفة .
فعّالة في المساحات العالية الأبعاد ومقاومة للإفراط في التخصيص .
مستخدمة بكثرة في تصنيف النصوص، والتعرف على الأنماط، وتحليل الصور .
تدعم النوى المختلفة (Kernels) للتعامل مع البيانات غير الخطية .
تتطلب ضبط دقيق للمعاملات وتدريب مكثف .
تعطي نتائج دقيقة خصوصًا عندما تكون الفئات واضحة الانفصال .
.7 خوارزمية Naive Bayes
تعتمد على نظرية بايز مع افتراض استقلالية السمات .
سريعة وفعالة، خصوصًا مع البيانات عالية الأبعاد مثل النصوص .
تُستخدم في تصنيف البريد العشوائي، وتحليل المشاعر، وتوقع الكلمات .
على الرغم من افتراضاتها البسيطة، إلا أنها تعطي نتائج جيدة .
تُعتبر من أفضل الخوارزميات لتصنيف النصوص الكبيرة .
تتعامل بشكل جيد مع مجموعات بيانات غير متوازنة .
من السهل تدريبها وتفسير نتائجها .
.8 خوارزميات التجميع (K-Means Clustering)
تُستخدم لتجميع البيانات إلى "K" مجموعات غير مصنفة مسبقًا .
تحدد مراكز التجمع (Centroids) وتقسّم النقاط وفقًا لأقرب مركز .
تُستخدم في تحليل السوق، تقسيم العملاء، واكتشاف الأنماط .
فعالة لكنها تتطلب تحديد عدد المجموعات مسبقًا .
تتأثر بمواضع الانطلاق العشوائية وقد تعاني من الحلول المحلية .
لا تُستخدم للتصنيف بل لاكتشاف البنية الكامنة في البيانات .
مناسبة جدًا في التحليل الاستكشافي للبيانات .
.9 خوارزمية الشبكات العصبية الاصطناعية (ANN)
مستوحاة من طريقة عمل الدماغ البشري، وتتكون من طبقات مترابطة .
تُستخدم في التنبؤ، التصنيف، وتحليل البيانات المعقدة .
تعمل بكفاءة على البيانات غير الخطية والمعقدة .
قادرة على التعلّم الذاتي وتكييف الأداء مع الوقت .
تُستخدم في تطبيقات مثل التعرّف على الصوت والصور .
تتطلب قدرًا عاليًا من البيانات والمعالجة .
تمثل الأساس في الذكاء الاصطناعي الحديث والتعلم العميق .
.10 الشبكات العصبية العميقة (Deep Neural Networks - DNN)
نسخة مطورة من ANN بعدد أكبر من الطبقات المخفية .
تُستخدم في المهام المعقدة مثل الترجمة الآلية، والتعرف على الصور .
قادرة على معالجة كميات ضخمة من البيانات واستخلاص السمات تلقائيًا .
تتطلب موارد حوسبة كبيرة وتدريب طويل .
تحقق نتائج مذهلة في مجالات الرؤية الحاسوبية والصوت .
تعمل على اكتشاف العلاقات العميقة في البيانات .
تمثل العمود الفقري للعديد من أنظمة الذكاء الاصطناعي الحديثة .
.11 خوارزمية تعزيز التدرج (Gradient Boosting Machines - GBM)
تُبنى على مبدأ الجمع بين عدة نماذج ضعيفة للحصول على نموذج قوي .
تقوم كل شجرة لاحقة بتصحيح أخطاء السابقة تدريجيًا .
تُستخدم في مسابقات البيانات نظرًا لدقتها العالية .
فعّالة جدًا في التصنيف والتنبؤ المعقد .
لكنها تتطلب وقت تدريب أطول مقارنة بخوارزميات أخرى .
تمثل أساسًا لتقنيات مشهورة مثل XGBoost و LightGBM.
تتميز بمرونة في الضبط الدقيق للنموذج .
.12 خوارزمية التكرار التوقعي (Expectation Maximization - EM)
تُستخدم لتقدير المعلمات عندما تكون بعض البيانات غير ملاحظة .
تعمل من خلال تكرار مرحلتين: التوقع والتعظيم .
مناسبة لنماذج البيانات غير المكتملة مثل تجميع البيانات الناقصة .
تُستخدم في تطبيقات مثل تحليل الصور والتصنيف الغامض .
تحتاج لضبط دقيق للبداية لتجنب الحلول المحلية .
توفر نتائج إحصائية قوية عند استخدامها بشكل صحيح .
مثالية للمشاكل التي تتطلب تعلّم غير مراقب .
.13 خوارزميات التعلم التعزيزي (Reinforcement Learning)
تعتمد على مبدأ "المكافأة والعقوبة" لتعليم النموذج اتخاذ قرارات .
تُستخدم في الألعاب، الروبوتات، والنظم ذاتية التعلم .
تتعلم من خلال التفاعل مع البيئة وتحسين الأداء عبر التجربة .
الخوارزمية لا تتلقى إجابة صحيحة مباشرة، بل تعزز الخيارات الناجحة .
قادرة على التكيف في البيئات المتغيرة والمعقدة .
تُستخدم في تقنيات متقدمة مثل AlphaGo وقيادة السيارات ذاتيًا .
تعتبر من أقوى طرق الذكاء الاصطناعي للقرارات المتسلسلة .
كيف تختار الخوارزمية المناسبة لتطبيقك ؟
اختيار الخوارزمية المناسبة لتطبيق الذكاء الاصطناعي يتطلب تحليلًا دقيقًا لعدة عوامل تقنية وبيئية تتعلق بطبيعة البيانات والأهداف المرجوة من النظام. وفيما يلي أبرز المعايير التي يجب أخذها بعين الاعتبار :
- طبيعة البيانات المتاحة :
نوع البيانات (مهيكلة أو غير مهيكلة)، وحجمها، وجودتها، وتوزيعها، كلها عناصر تؤثر بشكل مباشر على اختيار الخوارزمية. على سبيل المثال، الخوارزميات القائمة على التعلم العميق مثل الشبكات العصبية مناسبة للبيانات غير المهيكلة مثل الصور والنصوص، بينما تكون خوارزميات الانحدار أو الأشجار العشوائية أكثر فاعلية مع البيانات المهيكلة . - هدف التطبيق :
يجب تحديد ما إذا كان الهدف هو التصنيف، التنبؤ، التجزئة، الكشف عن الشذوذ، أو التوصية. فلكل هدف خوارزميات مخصصة تتناسب معه؛ مثل استخدام خوارزميات "SVM" أو "Random Forest" للتصنيف، و "Linear Regression" للتنبؤ . - الأداء والدقة المطلوبة :
إذا كان التطبيق يتطلب دقة عالية (مثل التطبيقات الطبية أو المالية)، فقد تكون الخوارزميات المعقدة والمكثفة حسابيًا مفضلة، حتى وإن كانت بطيئة في التدريب. أما في التطبيقات التي تتطلب استجابة سريعة، فقد يكون من الأفضل استخدام خوارزميات أقل تعقيدًا لكنها أكثر سرعة وكفاءة . - قابلية التفسير :
بعض الخوارزميات مثل "Decision Trees" أو "Logistic Regression" توفر مستوى عالٍ من الشفافية في النتائج، وهو أمر مهم في القطاعات التي تتطلب تفسيرًا واضحًا للقرارات، مثل الرعاية الصحية أو القانون . - إمكانيات الحوسبة المتوفرة :
بعض الخوارزميات تتطلب موارد حوسبية كبيرة، مثل وحدات معالجة الرسومات (GPUs) لتدريب نماذج الشبكات العصبية العميقة. لذا يجب التأكد من توفر البنية التحتية المناسبة قبل اختيار الخوارزمية . - قابلية التوسع والتحديث :
في التطبيقات التي تحتاج إلى التعامل مع بيانات متغيرة باستمرار، من الضروري اختيار خوارزمية يمكنها التكيف مع التغيرات دون الحاجة لإعادة التدريب الكامل .
بناءً على هذه المعايير، تتم عملية التقييم الأولي عبر تجريب عدة خوارزميات باستخدام مقاييس الأداء المناسبة، ثم اختيار الأنسب منها بناءً على نتائج التحليل العملي، وليس فقط النظري .
إن خوارزميات الذكاء الاصطناعي تمثل العمود الفقري للتقنيات الحديثة التي تدفع بالعالم نحو التحول الرقمي الكامل. ومع تعدد أنواع الخوارزميات واختلاف أساليب عملها، تظل الحاجة قائمة لفهم مزايا كل خوارزمية وتطبيقاتها العملية، لضمان الاستفادة القصوى منها في مختلف القطاعات. سواء كنت باحثًا، مطورًا، أو صاحب قرار، فإن الإلمام بهذه الخوارزميات يمنحك أدوات قوية لتحسين الأداء، ودعم الابتكار، واتخاذ قرارات أكثر ذكاءً. ومع استمرار تطور المجال، من المتوقع أن تظهر خوارزميات جديدة تفتح آفاقًا أوسع لما يمكن تحقيقه باستخدام الذكاء الاصطناعي .
4o



















